
日記+コメント付きブックマーク+他人にも役に立つかもしれない情報など。
(更新情報: RSS(ツッコミ付き) / RSS(ツッコミ抜き) / LIRS)
2006/10/04 編集
_ [Perl] HTML::TreeBuilder イイ
HTML の解析処理にはこれまで HTML::Parser とか HTML::TokeParser とか使ってきましたが、どちらもどうにもまどろっこしくてイライラしてました。
で、Perl で CSS セレクタ@naoyaのはてなダイアリーや HTML::Selector::XPath をリリース@blog.bulknews.net 等で HTML::TreeBuilder が使われているのを見て使ってみましたが、DOM っぽく操作できてかなりいい感じです。
とりあえず、指定した URL から HTML をゲットして画像の ALT 属性を展開しつつ全ての A 要素のリンクテキストと URL を表示するテスト
use strict;
use HTML::TreeBuilder;
use LWP::Simple;
use URI;
# 引数
die 'usage: foobar.pl URL' if ($#ARGV != 0);
my $url = $ARGV[0];
# HTML Tree 作成
my $tree = new HTML::TreeBuilder;
$tree->parse(get($url));
# alt 属性を持つ要素はそのテキストで置換する
for my $img ($tree->look_down('alt', qr/.*/)) {
$img->replace_with($img->attr_get_i('alt'));
}
# 全ての A 要素のテキストと URL と絶対化した URL を取り出す
for my $a ($tree->find('a')) {
print join("\t",
$a->as_text,
$a->attr_get_i('href'),
URI->new_abs($a->attr_get_i('href'), $url)
), "\n";
}
use HTML::TreeBuilder@hPod あたりも参考になりました。
というわけでさよなら HTML::TokeParser。
2006/10/05 編集
_ [Web制作] W3C、動的なウェブコンテンツのアクセシビリティ確保に向けたロードマップのドラフト公開
Roadmap for Accessible Rich Internet Applications (WAI-ARIA Roadmap)
W3Cは26日(現地時間)、JavaScriptやAjax、DHTMLなどを用いた動的なウェブコンテンツのアクセシビリティに関するロードマップの草案を公開した。
[A.A.O. - 最新ニュースより引用]
ということで、Ajax 花盛りでアクセシビリティがないがしろになりつつある昨今 (そんな中 Google は Google Maps といい GMail といい、Ajax 不使用版もきっちり用意していて凄いなあとただただ関心するのですが)、どうやって RIA とアクセシビリティを両立していくのか、非常に興味深いところです。
2006/10/09 編集
_ [音楽] sonarsound tokyo 2006
の5本立て。
生ヤン富田キター! 生ノバクキター! スチールドラムキター!
3.5時間立ちっぱなしでヘロヘロの身に冒頭20分のあれはきつかったですが…
ついでにゲスト出演の小山田君が全然目立たなくて、他のメンバーのように出番もなく影の薄い存在になってしまってました。もったいない…
ヤン富田以外では、最初の Maxence Cyrin の力強いピアノ演奏がナイスでした。
B000BQORES
クリックしちゃって良いのかn
ついでにヤン富田の分もアサマシエイトリンクしておきます。
B000FBG35U
B000J107J4
DOOPEE TIME 2 はいつになったら Amazon に入るんでしょうか…
2006/10/10 編集
_ [Perl] HTML::FillInForm に感動した
これまでもお名前はちらほら聞いておりましたが、初めて使いました。
- HTML::FillInForm - HTML フォームにCGIデータをすまわせる@perldoc
- シンプルなWebアプリなCGIを書いてみる@blog.nomadscafe.jp
- Template Toolkitとは@はてなダイアリー
- HTML-FillInForm@CPAN
- Template-Plugin-FillInForm@CPAN
素晴らしい…!
フォームの上部にエラーをまとめて表示して、入力した文字列もそのままHTML::FillInFormで復元されてます。簡素なエラー画面でブラウザの戻るボタンを押す必要もありません。戻るボタンを押したときにいままで入力していた物がなくなっているということもないです。
[シンプルなWebアプリなCGIを書いてみる@blog.nomadscafe.jpより引用]
そう、その「フォームに記入ミスがあったら、エラーを表示して戻らせるのではなく、記入済みの部分を埋めたフォームを再表示する」のは Web アプリ開発における基本中の基本ですが、それを実装するのはなにげにちょっぴり面倒で、プログラム側もテンプレート側も泥臭い冗長な記述になりがちでした。でも FillInForm 使うと、特にチェックボックスやラジオボタン、リストボックスがある場合は大幅に負担減ですよ。非常にすっきりしました。元となるフォームの作成があくまでテンプレートで行えるのも(が?)素晴らしい。
それにしても、自分が root 持ってるサーバでモジュール使いたい放題だと開発が実に楽になりますね…。
ものによってはファイル置くだけで済む Pure Perl なものも多いんでしょうが、apt-get と cpan 一発で済む手軽さには代え難いものがあります。
最近走らせたコマンド↓
apt-get install apache2
apt-get install libapache2-mod-fcgid
apt-get install libcgi-fast-perl
apt-get install libwww-perl
apt-get install libunicode-japanese-perl
apt-get install libtemplate-perl
apt-get install libhtml-fillinform-perl
cpan install Template::Plugin::FillInForm使いたいと思う Perl モジュールのほとんどが公式パッケージ化されてる Debian にも感心します。
2006/10/17 編集
_ [プログラム] 東京大学教養課程の第一プログラミング言語がRubyに@sumiiの日記
漏れが大学に入った時必修だった情報処理 Ic は C で、2つ下の代から Java に変わりましたが、どちらも理工系でない学部の1年生全員にいきなり触らせるには相応しくない言語だと思ってました。(最近の SFC はどう変遷してるんでしょうか?)
「プログラムを書いてコンピュータを働かせる」ことを学ぶ以前に、型やポインタ、参照、オブジェクト、etc...といった抽象的で煩わしい概念でプログラミングアレルギーを発生させてたら、せっかく必修で受講させても世間で役に立てられないだろうと。教養として必修でやらせるなら Perl とか (今風に言えば Ruby や Python を含めた LL 全般のいずれか) がいいんじゃねえの、と思ってました。
というわけで、教養課程の第一プログラミング言語に Ruby というのは非常に正しい選択だと思った夕刻でした。
_ [他] シャープ、W-ZERO3[es]のメールソフトを改善するアップデータ@ケータイWatch
予約してない時間帯に突然アラームが鳴り出す不具合とか、呼び出し音が全く鳴らない不具合とか、直ってるんでしょうか…orz
2006/10/18 編集
2006/10/19 編集
_ [プログラム] PostgreSQLから『Ludia』でSennaの全文検索エンジンを試した@Kawa.netブログ
発表の仕方に関しては「それ何て Senna バインディング?」(2)と揶揄されてた Ludia でしたが、まあリビルドが必要な MySQL バインディングより使いやすそうなんでね?
_ [システム運用] Hyper Estraier ベースの Web 検索システム
というわけで、ここ3週間くらいの間、土日を中心に構築作業を行ってきた検索サーバを仮公開しました。
構築に関する情報はまた追ってまとめたいと思います。
Hyper Estraier API マンセーですよ。(そして Kabayaki にはもう二度と関わりたくない)
ところで1.4.6が公開されてますね。今回は時期的な関係で1.4.4で構築しましたが、1.4.5で追加されたハイライト付きプロキシは大変魅力的です。Google キャッシュに近い利便性を提供できると。PDF でも HTML 変換された状態で閲覧できると。任意の文字列のスニペットを簡単に作る裏APIもありがたいですね。
2006/10/20 編集
_ [Perl] Shibuya Perl Mongers テクニカルトーク #7@Shibuya.pm
速攻で埋まって席を取れませんでした。残念。
幸い今回は
2006年10月20日(金)に開催されるShibuya Perl Mongers テクニカルトーク #7をネット中継させていただきます。(予定)
[Shibuya Perl Mongers テクニカルトーク #7より引用]
というのも予定されているようなので、うまく都合つけて視聴したいところです。ありがたや…
_ [ネット諸々] グーグル、無料の乗換案内サービス「Google トランジット」@ケータイWatch
グーグル、無料の携帯版乗り換え案内サービス開始@ITPro
グーグル、携帯電話向け乗り換え案内“Google トランジット”を開始@ASCII24
100万回ブクマし…ようと思ったら、W-ZERO3 から google.jp にアクセスすると PC 向けサイトにリダイレクトされてしまう。どうしたらいいですか
2006/10/22 編集
_ [Web制作] Googleのトップページは、テーブルレイアウト@悪徳商法?マニアックス ココログ支店
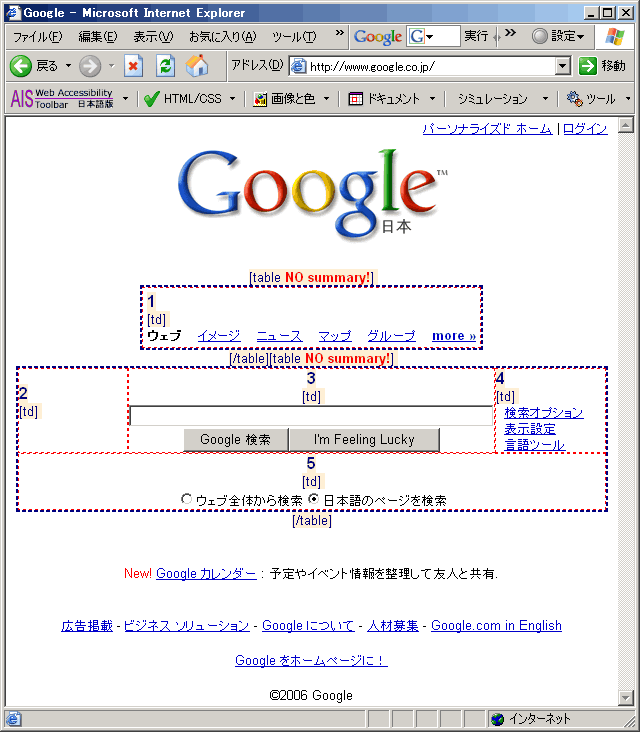
というわけで Web Accessibility Toolbar で TABLE 構造とセルの順番を表示するテスト。
2〜4のようにブロック要素を局所的に横に並べるのは TABLE じゃないとめんどいよね。何の害もないし。
1と5はわざわざ TABLE を使う必要ない気がしますが。
_ [Web制作] 無断リンク問題で渦中のYokoさんとチャットで話した。@Onlooker+beta
昨今はてブ - 無断リンクやはてブ - tinycafeで無断リンク禁止ネタがホットですが、
無断リンク問題で渦中のYokoさんとチャットで話した。その1@Onlooker+beta
無断リンク問題で渦中のYokoさんとチャットで話した。その2@Onlooker+beta
無断リンク問題で渦中のYokoさんとチャットで話した。その3@Onlooker+beta
これはすごい。
(俺も含めて) 多くの取り巻きがただ祭ってる中、真剣に冷静に対話して理解を得ようとしている姿に感動した。
tinycafe の中の人は過去のトラウマと激しい思いこみによって無断リンクは悪いものと思いこんでしまってるのですね。
2006/10/23 編集
_ [Web制作][Perl] Referer 情報をタグクラウド風に表示する Google Search Cloud を試してみた
Googleの検索語によるタグクラウド「Google Search Cloud」@GIGAZINE
(てきとーに翻訳)
以下の Perl プログラムは Apache HTTP サーバの access_log 拡張形式を解析し、Google で検索されたページの referer を収集します。
リクエストは Web ページとステータスコード毎に分類されます。
そして、Web 2.0 的なサイトでよく見られるタグクラウドのようなものを HTML 4.01 Strict に準拠した Web ページとして出力します。
[Google Search Cloudより引用]
おもろい。
というわけで先月分のログを食わせてみました。
ここはマンガミーヤ関連サイトじゃないとあれほど言ったのにまだわから(ry
さて、気づいた点
- query が UTF-8 でない場合は化ける
- 全角空白はキーワードの区切りとして認識されない…いや、半角空白すら split されない?
欧米人が作ってるんだから仕方ないところでしょうか。
tDiary の disp_referer プラグインにも同様のオプションが付くと面白いかもしれません。
ページがどんなキーワードで検索されたかをTagCloud風に表示させるくっつきサービス@YappoLogs
これも面白そうですね。
_ [Web制作][Perl] Google Search Cloud 日本語対応など
というわけで、Google Search Cloud をちょっと改良して、
- UTF-8 でない日本語検索語でも文字化けしないように (完全ではない)
- 全角/半角・大文字/小文字を同一視
- リンク元の検索ページにジャンプできるように
- ファイル名を省略した場合は標準入力から入力
してみますた。
結果 (上位20位のみ) (使った gscloud-jp.pl)
それにしても、時々 「\x83}\x83\x93\x83K\x83~\x81[\x83\x84」のように、本来 % であるはずのところが \x に置き換わった Referer が入ってくることがあるのだが、なぜなのだろうか。Referer アドレスに直接飛んでもやっぱり化けてるんですが、手動で \x を % に置換してやると正常に戻る謎。
2006/10/24 編集
_ [健康志向] Status Report
x49.0kg
18.4%
1.0km/21min (jog)
1.0km/20min (jog)
1.0km/20min (jog)
0.5km/12min (walk)
_ [ネット諸々] Amazon.co.jp、最速で注文当日に商品が届く「お急ぎ便」試験提供@INTERNET Watch
それより通常サービスが発送 (Amazon) も配送 (佐川) も異様に遅いのをなんとかしてくれないものでしょうか…。
サービス開始当初は「すげー、翌日に届くよ」って驚嘆したもんですが、最近1週間はざらですょ
2006/10/25 編集
2006/10/27 編集
_ [Perl] Encode.pm, Jcode.pm, Text::Iconv のベンチマーク比較@Public Diary
Encode.pm Jcode.pm のベンチマーク比較@isoya9の日記
なるほど。
あと Unicode::Japanese と jcode.pl も加えて、自動検出の使用・不使用での差も見たいところですね。
_ [Perl] Encode, Text::Iconv, Unicode::Japanese, Jcode, jcode.pl のベンチマーク比較
というわけで、やってみました。
- 入力コードの自動判別機能を持つモジュールはそれを使った場合 (guess) と使わない場合 (fixed) 両方でテスト
- jcode.pl は型グロブ渡し (grob) 参照渡し (ref) 両方をテスト
- jcode.pl はキャッシュ使用 (cache) 不使用 (nocache) 両方をテスト
- jcode.pl は utf8 をサポートしてないため、sjis との変換で。ただし他のモジュールとの不公平が出ないよう、他のモジュールでは utf8 だけでなく sjis との変換もテスト。
- 実行環境は Pentium 4 3.06GHz マシン + Windows XP SP2 + coLinux 0.6.4 + Debian GNU/Linux 3.1 + Perl 5.8.4 (Encode 1.99 + Text::Iconv 1.2 + Unicode::Japanese 0.23 + Jcode.pm 0.88 + jcode.pl 2.13)
- Jcode と Unicode::Japanese は Debian パッケージの XS 版のほか、同バージョンの PP 版、最新の PP 版 (Jcode 2.06, Unicode::Japanese 0.38) でもテスト
使ったコード … jcodebench.pl
変換速度の比較
jcode::convert(guess-sjis-grob-nocache) 84746/s jcode::convert(guess-sjis-grob-cache) 84746/s jcode::convert(fixed-sjis-grob-nocache) 53763/s jcode::convert(fixed-sjis-grob-cache) 50505/sJcode::convert(fixed-utf8-xs088) 37594/s Text::Iconv(fixed-utf8) 36496/s Text::Iconv(fixed-sjis) 34722/s Encode::from_to(fixed-utf8) 31250/s Encode::from_to(fixed-sjis) 29070/s Jcode::convert(fixed-utf8-pp206) 21739/s Jcode::convert(fixed-sjis-pp206) 21739/s Unicode::Japanese::new(fixed-sjis-xs) 18868/s Unicode::Japanese::new(guess-sjis-xs) 16447/s jcode::convert(fixed-sjis-ref-cache) 12755/s Unicode::Japanese::new(fixed-utf8-xs) 12107/s jcode::convert(fixed-sjis-ref-nocache) 11737/s Unicode::Japanese::new(guess-utf8-xs) 10941/s Jcode::convert(fixed-sjis-pp088) 10121/s Jcode::convert(fixed-sjis-xs088) 10081/s jcode::convert(guess-sjis-ref-nocache) 6676/s jcode::convert(guess-sjis-ref-cache) 6274/s Jcode::convert(guess-sjis-pp206) 5945/s Jcode::convert(guess-utf8-xs088) 5507/s Encode::from_to(guess-utf8) 5359/s Jcode::new(guess-sjis-pp206) 5336/s Encode::from_to(guess-sjis) 5297/s Jcode::new(guess-utf8-xs088) 5056/s Jcode::convert(guess-utf8-pp206) 5035/s Jcode::convert(guess-sjis-xs088) 4608/s Jcode::convert(guess-sjis-pp088) 4608/s Jcode::new(guess-utf8-pp206) 4583/s Unicode::Japanese::new(fixed-utf8-pp038) 4230/s Jcode::new(guess-sjis-pp088) 4205/s Jcode::new(guess-sjis-xs088) 4191/s Jcode::convert(fixed-utf8-pp088) 3751/s Unicode::Japanese::new(fixed-utf8-pp023) 3613/s Unicode::Japanese::new(fixed-sjis-pp038) 3544/s Unicode::Japanese::new(fixed-sjis-pp023) 2831/s Jcode::convert(guess-utf8-pp088) 2374/s Jcode::new(guess-utf8-pp088) 2255/s Unicode::Japanese::new(guess-utf8-pp038) 2199/s Unicode::Japanese::new(guess-sjis-pp038) 2056/s Unicode::Japanese::new(guess-utf8-pp023) 1910/s Unicode::Japanese::new(guess-sjis-pp023) 1707/s
変換速度についての考察
- Encode, Jcode, jcode.pl (参照渡し) では、文字コードを自動判別させるとかなり遅くなるが、Unicode::Japanese は変わらない。
jcode.pl (型グロブ渡し) はなぜか自動判別させた方が速くなる? (んなアホな…) 特に型グロブ渡しの jcode.pl が異常に速い (jcode.pl の私的な解説書 によれば「perl5 のリファレンスの方が、perl4 の型グロブ形式よりも高速です。」となっているのだが…) 何かの間違いではないのか?→ 何かの間違いでした。詳しくは文字コード > jocode.pl, Jcode.pm, Encode.pmのパフォーマンス比較/一番速いのはどれ?を参照ください。- Jcode の入力コード自動判別は XS の有無に関わらず遅い
- 入力コードの自動判別をしなければ、Jcode.pm 2.0 以降は「Jcode 2.0 より、お使いの Perl Version が 5.8.1 以降の場合は Encode の Wrapper として機能するようになりました。」というだけあって、XS が使えなくてもかなりいける
- XS が使えない場合 Unicode::Japanese はあらゆる面で最弱
- Jcode 0.88 も XS が使えない場合は Unicode::Japanese に肉薄する遅さ
モジュールのロード速度の比較 (Public Diary 同様に100回繰り返しの測定)
jcode.pl real 2.073s user 1.390s sys 0.690s Text::Iconv real 3.336s user 1.840s sys 1.480s Jcode (XS 0.88) real 3.923s user 2.670s sys 1.240s Jcode (PP 0.88) real 3.939s user 2.740s sys 1.200s Encode real 4.244s user 2.030s sys 2.210s Unicode::Japanese (PP 0.23) real 4.919s user 2.590s sys 2.320s Unicode::Japanese (XS 0.23) real 4.930s user 2.940s sys 1.980s Unicode::Japanese (PP 0.38) real 4.977s user 2.730s sys 2.240s Encode + Encode::Guess real 5.137s user 2.660s sys 2.480s Jcode (PP 2.06) real 10.658s user 6.420s sys 4.230s
モジュールロード時間の考察
- 入力コードの自動判別が不要なら Text::Iconv が最速
- 入力コードの自動判別が必要なら Jcode 0.88 が最速
- Jcode, Unicode::Japanese ともに XS 版と PP 版でロード時間の差は見受けられない
- Jcode 2.06 のロード時間が目立って遅い
- …どれも0.1ミリ秒以下だし、そもそもロード時間なんかどうでもいいという噂も
どのモジュールを選ぶのが良いのか (速度的な面から)
- 入力コードの自動判別が不要なら Text::Iconv が最速 (でも Text::Iconv と Encode との差は僅かだから、Encode でいいんじゃね? 標準モジュールだし)
- 入力コードの自動判別が必要なら Unicode::Japanese (XS) が最速
- Jcode は遅いので、以下の2つのケースを除いて使うメリット無し
- Perl 5.8.0 以前で、XS が使えない場合は Jcode が有用
- Perl 5.8.1 以降で、XS が使えず文字コード自動判別が必要な場合は Jcode が若干有用 (ただしこれも Encode::Guess との差は極僅か。…でも Encode::Guess 使いづらいし)
ということになるのでしょうか。
使い勝手とか判別精度とか無視してるので、速度だけで決めることはできないですが。
まああと
- それぞれ自動判別の精度やクセ・不具合は?
- もっと長大な文字列を与えた場合は?
といった点について考慮する必要がありそうです。
個人的には Unicode::Japanese の隠しメソッドが魅力的なので Unicode::Japanese が基本になりつつあります。
(追記) 「Unicode::Japanese は全角半角変換させると遅いょ」という話があったのでメモ。でも Encode::JP::H2Z は内部処理が EUC-JP で行われてるのが嫌げです。
(追記) jcode.pl の型グロブ渡しは実際には何もしてないから爆速で当然だよというツッコミがあったので修正。
2006/10/28 編集
_ [日記/blog] サッポロ飲料が社内ブログで情報共有、4月から全社員500人で活用@ITPro
だいぶ昔の記事ですが。
システムを構築したのは日立製作所。採用したブログ・ソフトは日立の「BOXERBLOG/iB」、RSSリーダーはWebベースの「BOXERBLOG Sonar」。導入費用は、ソフト、ハード代とシステム構築費用込みで約1000万円である。
[サッポロ飲料が社内ブログで情報共有、4月から全社員500人で活用より引用]
500人が使うブログが1000万円って高くないですかね。
適当に内訳を推測すると
- HA8000/110EE 適当にカスタマイズ×2: 100万くらい
- BOXERBLOG/iB 500ユーザライセンス: 158万
- BOXERBLOG Sonar 500ユーザライセンス: 158万
- システム構築: 600万弱
SI 費高くね? もう少しハードウェアを手厚くしてるのかもしれないが。
ちなみに Movable Type と Fresh Reader で組んだ場合は
- Movable Type 10ユーザライセンス×50: 236万
- Fresh Reader ユーザー数無制限版: 82万
総額では変わらんですね… (MT 高けぇ)
商用のブログ製品って高いなあ。
2006/10/29 編集
2006/10/31 編集
_ [体調不良] 虫歯はなめてると治療に1年とかかかりますy
y 虫歯はなめてると治療に1年とかかかりますy、、、根元の方がいっちゃうとやばいらしい
p 根元まで逝きました
p 死ぬ…
y サヨナラ
p 神経抜いたのになんでこんな痛いの…
y なんど治療しても全然なおらなくて大学病院とかにいかされます
y あーやばいパターン
p majide
y こまかい神経?がのこっちゃってるとかで
p sou
y また穴あけてごりごりやられたりする
y 同僚と上司が同じ目にあっています
p 毎日ゴリゴリやられます
p そろそろ収まる頃だと歯医者たんは言ってるのですが
y 同僚はそういわれてからも全然痛みがおさまらず
y 大学病院いってますねー
y そして、1年かかると言われたらしい
…ネタだよね
うーん
_ [健康志向] 基礎代謝を高めるための99の技法
[あとで読む]
_ ぎり [オオアリクイが連呼されててワラタ]